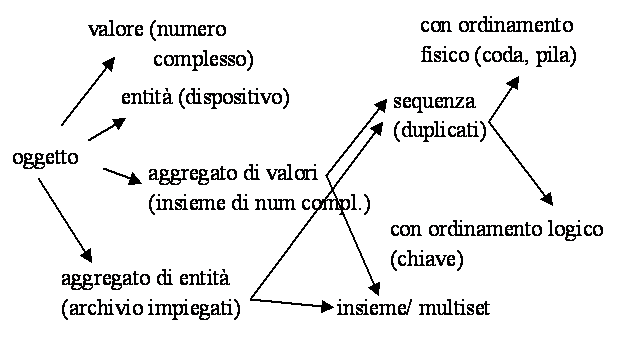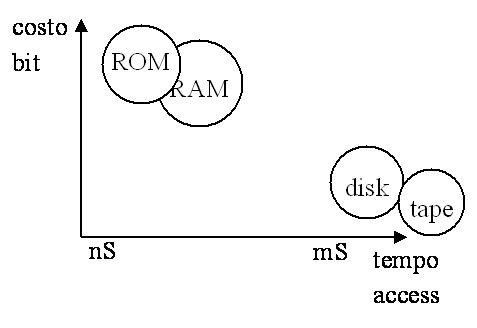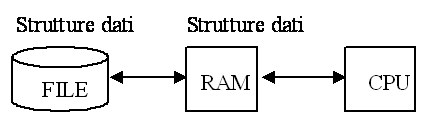|
|
| tecnica |
|
CENNI STORICI
Meccanizzazione dell'aritmetica
la numerazione romana e araba
Abacus
Sommatore meccanico di Pascal (1642) e di Liebniz (1670)
Calcolatrice tascabile
Programma memorizzato per controllo calcoli
Telaio automatico di Jacquard (programma su nastro di schede perforate metalliche - 11000 in 10 anni) => automazione, impatto sociale
Analytical Engine di Babbage (progetto) programma letto da due nastri perforati (istruzioni, operandi), memoria interna (1000 registri da 50 cifre), meccanismi per calcoli e per trasferimento dati tra componenti. Movimento del nastro per generare flussi non sequenziali di esecuzione (programma esterno).
Hollerith introduce i sensori elettrici per leggere schede perforate (1896 fonda la società che darà origine all'IBM (1924)).
Studi teorici: codifica binaria per decimali e in virgola mobile, Macchina astratta di Turing, applicazione dell'algebra di Boole alla progettazione hardware (Shannon ),..
Calcolatore elettromeccanico MARK I (IBM) - Analytical engine (programma esterno).
Calcolatori elettronici: ENIAC(Univ. Pennsylvania-l946) a valvole, lungh. 30 mt., 150KW, 300 volte + veloce di MARK I, programma interno cablato nell'hardware (caricamento lento), bassa affidabilità.
La macchina di Von Neumann (concetto di programma registrato in memoria e modificabile)
La macchina di Von Neumann
nastri infiniti di caselle che possono contenere un numero
memoria per contenere informazioni durante l'elaborazione
CPU: elabora l'informazione (ALU) e trasferisce l'informazione tra i componenti con riferimento a indirizzi fisici
IAS machine di Von Neumann-Univ. Princeton (1KRAM tubi williams, t.a. 25microsec.), Whirlwind-Bell (2KRAM nuclei magnetici t.a. 25 microsec.), EDSAC-Univ.Cambridge, UNIVAC
Linguaggio assembler
Wilkes ha l'idea della mprogrammazione T 1964 IBM 360 (mprogr.)
2a generazione: transistor (meno potenza, spazio e calore e più affidabilità) memorie a nuclei magnetici, dischi a testine mobili.
tecnica dell'interruzione, multiprogrammazione, applicazioni gestionali superano quelle numeriche, applicazioni nell'automazione, il problema del software (i costi dell'hardware diminuiscono e aumentano quelli del software), ingegneria del software
FORmula TRANslator (Backus-IBM), 1960 COmmon Business Oriented Language, 1959 LISP, 1960 Algol (principi di programmazione strutturata), 1962 BASIC
3agenerazione: circuiti integrati (IBM360), memorie a semiconduttore, cache, reti, calcolatori paralleli, microprogrammazione CPU, minicomputer
Pascal (didattica), PL/1, C(software di base), Prolog, timesharing, memoria virtuale, miglioramento compilatori
dal 1975-80 4agenerazione: VLSI, PC, memorie ottiche, multiprocessori, reti locali, robotica, Client-Server
strumenti per l'utente finale, multimediale, realtà virtuale, internet, pirateria, Microsoft (milioni di esemplari a basso prezzo), ADA, Linguaggi ad oggetti (C++, Java)
Cos'è l'Informatica?
La scienza della rappresentazione e dell'elaborazione dell'informazione
PROCESSO DI RISOLUZIONE DI UN PROBLEMA
Definizione di problema:
Classe di domande omogenee che trovano una risposta tramite una procedura uniforme.
Ogni specifica domanda è un'istanza del problema.
Esempi:
a) trovare il maggiore tra 12 e 24
b) trovare il numero di Rossi in un elenco telefonico
c) determinare la somma dei numeri interi da 1 a 100
e) calcolare il massimo comun divisore tra 12 e 132.
f) trovare tutti i valori di n tali che Zn=Xn+Yn con X,Y,Z interi
Come affrontare un problema:
non limitarsi a trovare la soluzione alla specifica istanza di un problema, ma cercare la soluzione al problema;
sapere che lo strumento fondamentale di cui dotarsi è la capacità di costruire modelli (rappresentazioni mentali della realtà in esame) e di una metodologia;
saper scegliere la tecnologia adatta senza rimanerne condizionati.
Risolvere un problema significa: 'cercare consapevolmente delle azioni appropriate per raggiungere uno scopo chiaramente concepito, ma non immediatamente perseguibile' Mathematical discovery, 1961
Una trasformazione "F", (anche informale) che trasforma i dati in ingresso del problema in dati in uscita in modo efficace.
F può esistere, ma essere ambigua o imprecisa (se esistono due Rossi nel problema b), oppure non esistere (problema f).
Esempi:
Problema 1. Sommare i numeri interi da 1 a 100 (istanza del problema: sommare i numeri interi positivi da 1 a N con N pari).
Algoritmo 1:
somma= 0; per numero che va da 1 a N ripeti somma= somma + numero
Algoritmo di GAUSS:
considerando che 1+N= =3+(N-2) => somma = (1+N)*N/2
Problema 2. Determinare il massimo comun divisore (MCD) di 12 e 132 (istanza del problema: determinare z=MCD(x,y) con x,y,z I N+).
Algoritmo 1.
Divisori di x (y). D(x (y))=
MCD(X,Y) = max (D(X) D(Y))
Algoritmo di Euclide
a)Siano X,Y,R I N+ e v I N. Se X = v * Y + R allora
Teorema 1: D(X) D(Y) = D(Y) D(R) TMCD(X,Y) = MCD(Y,R)
b)Siano X,Y I N+ e v IN. Se X = v * Y allora
Teorema 2: MCD(X,Y) = Y
- F non è necessariamente definita nella sua realizzazione e può quindi essere non calcolabile con lo strumento a disposizione.
- F deve comunque sempre essere corretta.
Requisiti:
identificazione di un ESECUTORE (manuale/automatico) dell'algoritmo;
definizione di un LINGUAGGIO comprensibile all'esecutore e a chi implementa l'algoritmo
L'algoritmo implementato consiste nella traduzione dell'algoritmo risolvente tramite il linguaggio scelto.
ogni azione non è ambigua per l'esecutore;
ogni azione è eseguibile dall'esecutore in un tempo finito;
l'esecuzione ordinata delle azioni termina dopo un numero finito di passi.
Tipi di algoritmi
deterministici (ad ogni azione segue al più un'azione successiva)
non deterministico (un'azione ammette più azioni successive con scelta arbitraria)
probabilistico (un'azione ammette più azioni successive dotate di distribuzione di probabilità)
Osservazioni:
esistono più algoritmi implementati per lo stesso algoritmo risolvente;
un algoritmo implementato deve essere sempre corretto;
la scelta dell'algoritmo implementato dipende:
dall'efficienza dell'esecutore (tempi e uso risorse);
dall'efficienza richiesta all'algoritmo (tempi).
Problema:
Dati due numeri interi X e Y eseguire la moltiplicazione Z=X*Y
Linguaggio riconosciuto dall'esecutore:
a. Somma, sottrazione, assegnamento
b. Test valore = 0 ?
c. Legge e scrive valori interi a video
Una prima rappresentazione dell'algoritmo implementato
(diagrammi a blocchi)
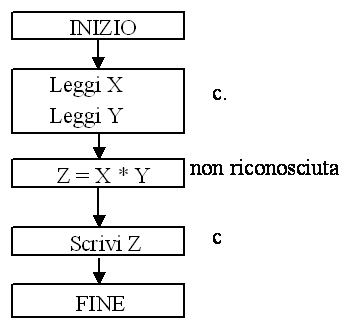
Espansione blocco non riconosciuto

L'algoritmo è corretto per X = 2 e Y = 3, ma non in generale.
Riformulazione per considerare il caso X = 0
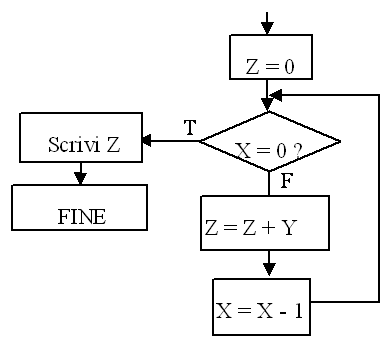
L'esecutore Calcolatore (la macchina astratta di Von Neumann)

Il linguaggio simbolico (DI PROGRAMMAZIONE) riconosciuto dall'esecutore:
Istruzioni
[W:] ADD X,Y : valore(parola Y) = valore(parola Y) + valore(parola X)
[W:] MOV X, Y: valore(parola Y) = valore(parola X)
[W:] BR I: passa ad eseguire l'istruzione in parola I
[W:] BEQ X, I: se valore(parola X) =0 allora SALTA I
[W:] EXIT termina esecuzione programma
[W:] READ X: carica valore letto da nastro ingresso in parola X
[W:]WRITE X: scrive su nastro di uscita valore(parola X)
Direttive (pseudoistruzioni)
[X:] RES N Alloca N parole consecutive in memoria (RAM) e associa
l'indirizzo simbolico X(etichetta) alla prima parola
[X:] INT N Alloca 1 parola in memoria associata a X e vi carica N
END [X] indica la fine del programma e la posizione della prima istruzione da eseguire
L'algoritmo implementato (chiamato PROGRAMMA) della moltiplicazione (linearizzazione schema a blocchi)
etichette direttive/istruzioni
X: RES
Y: RES
Z: RES
ZERO: INT 0
NOTUNO INT -l
START: READ X
READ Y
MOV ZERO, Z
CICLO: BEQ X, FINE
ADD Y, Z
ADD NUNO, X
BR CICLO
FINE: WRITE Z
EXIT
END START (prima istruzione eseguibile)
Caricamento in memoria a partire dalla parola di indirizzo 0.
Etichetta indirizzo
|
X |
|
|
|
|
Y |
|
|
|
|
Z |
|
|
|
|
ZERO |
|
|
|
|
NUNO |
|
|
-l |
|
START |
|
|
READ X |
|
|
|
|
READ Y |
|
|
|
|
MOV ZERO, Z |
|
CICLO |
|
|
BEQ X, FINE |
|
|
|
|
ADD Y, Z |
|
|
|
|
ADD NUNO, X |
|
|
|
|
BR CICLO |
|
FINE |
|
|
WRITE Z |
|
|
|
|
EXIT |
|
|
|
|
|
Esecuzione moltiplicazione con Y=4 e X=2
Program Counter (PC) è caricato con l'indirizzo 5 (END START)
|
indirizzo corrente |
Istruzione |
PC dopo esecuz. Istruz. |
X |
Y |
Z |
|
|
|
|
|
|
|
|
|
READ X |
|
|
|
|
|
|
READ Y |
|
|
|
|
|
|
MOV ZERO, Z |
|
|
|
|
|
|
BEQ X, FINE |
|
|
|
|
|
|
ADD Y, Z |
|
|
|
|
|
|
ADD NUNO, X |
|
|
|
|
|
|
BR CICLO |
|
|
|
|
|
|
BEQ X, FINE |
|
|
|
|
|
|
ADD Y, Z |
|
|
|
|
|
|
ADD NUNO, X |
|
|
|
|
|
|
BR CICLO |
|
|
|
|
|
|
BEQ X, FINE |
|
|
|
|
|
|
WRITE Z |
|
|
|
|
|
|
EXIT |
|
|
|
|
(simulazione di un assemblatore - collegatore/linker)
Regole di traduzione:
Memoria costituita da parole da 16 bit.
Numeri: 16 bit con primo bit di segno (1 significa <0).
Indirizzi: si utilizzano 6 bit (indirizzi tra 0 e 63).
|
Codifica istruzioni |
Codice operativo |
operando 1 |
operando 2 |
|
|
|
|
|
|
Istruzione |
C.O. |
|
|
|
|
|
MOV 1000
ADD 0110
READ 1111
WRITE 0111
BR 1001
BEQ 1010
EXIT 1011
Programma in linguaggio binario (caricamento in memoria a partire dall'indirizzo 0 - PC = 000101)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
L'esecuzione del programma
Le istruzioni sono interpretate ed eseguite dalla CPU, eseguendo il microprogramma memorizzato nella ROM della CPU
Schema di un microprogramma:
sino a quando il calcolatore è acceso ripeti
(*fase di fetch*)
carica in Registro Istruzione corrente (CIR) il valore
della parola(indir. in PC)
INC(PC)
(*decodifica codice operativo*)
CASE CIR.Codice Operativo OF
0110(SOMMA):
AR(registro indirizzi mem.) = CIR.operando1
legge in memoria e carica in DR(registro dati mem) operando 1
Ra= DR
AR(registro indirizzi mem.) = CIR.operando2
legge in memoria e carica in DR(registro dati mem) operando 2
Rb= DR
Rb = sommatore ALU (Ra,Rb)
DR =Rb
scrive in memoria risultato in operando 2
1001(SALTA): PC = CIR.operando
END (*case*)
END (*while*)
Perché il linguaggio simbolico?
Astrazione (nomi simbolici) e facile modificabilità del linguaggio simbolico
|
Programma 1 |
Programma 2 |
|
X: RISERVA |
Y: RISERVA |
|
Y: RISERVA |
X: RISERVA scambio |
|
ZERO: |
ZERO: |
|
NUNO: |
TEMP: nuova variabile |
|
|
NUNO: |
Indipendenza del linguaggio binario dalla memoria
|
|
Memoria centrale |
|
|
|
|
Caricamento |
|
|
SOMMA Y, Z |
Indipendente |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SOMMA Y, Z |
|
|
192 |
|
|
|
|
Memoria centrale |
|
|
|
|
Caricamento |
|
|
|
fisso |
|
|
|
|
Dal linguaggio simbolico ai linguaggi di terza generazione
/*linguaggio C*/
#include <stdio.h>
int X, Y, Z;
main()
printf("%d",Z);
Astrazione ed efficienza

Il calcolatore come macchina virtuale
|
|
|
|
Linguaggio C |
|
|
|
Esecutore C |
|
|
|
|
ling. simbolico |
|
|
Esecutore simbolico |
|
|
|
|
|
ling. binario |
|
Esecutore Binario |
|
|
|
|
|
|
CPU e Processo |
esecutore reale |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
INTRODUZIONE alla programmazione
Il Linguaggio C
La sintassi (una delle componenti della grammatica)
Descrive le regole per la composizione dei programmi
Determina il comportamento del programma
La notazione Backus Naur Form (BNF) per le regole della sintassi
(Appendice D1 e D2)
Elementi di una regola:
terminali: parole chiave del linguaggio (float, int), simboli di operazioni (+), numeri, stringhe e identificatori (costruiti con cifre e lettere senza spazi), punteggiatura (; in bold)
non terminali: identificatori di altre regole (in corsivo).
metasimboli: simboli del linguaggio BNF che servono a specificare scelta (A | B), opzionalità (opt) e ripetizione zero o più volte (0+) oppure 1 o più volte (1+).
Una regola:
non terminale ::= sequenza di terminali, non terminali e metasimboli.
Assioma (simbolo iniziale) e derivazione
Esempi (Appendice C: I e II parte):
identifier ::= letter 0+
letter ::= A |
digit ::= 0 |
expression::= constant_value | . | relational_expression |
logical_expression | arithmetic_expression
relational expression::= expression rel_op expression
logical_expression::= expression log_op expression
rel_op::= == | != | > | >= | < | <=
log_op::= || | && | !
La semantica:
priorità differenziata degli operatori (Appendice B)
/ *
< <= > >=
== !=
&&
ordine di esecuzione da sinistra verso destra (in generale),
lettere maiuscole e minuscole sono considerate diverse.
INTRODUZIONE AL LINGUAGGIO C
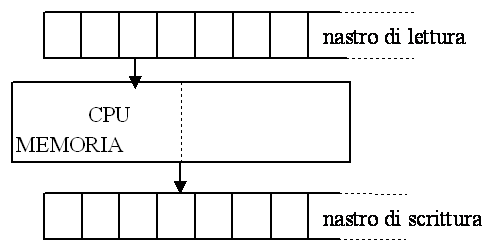
La macchina astratta C
nastro di lettura (standard input -> tastiera)
nastro scrittura (standard output -> video)
CPU e memoria
mancanza registri e nozione di variabile
espressioni e istruzioni più complesse rispetto al linguaggio assembler
Schema base di un programma.
Regole BNF:
program ::= directive_part opt void main ()
directive_part ::= ..#include identifier
global-declarative part ::= constant_declarations | type declarations |
variable_declarations
variable_declarations
declarative_part (per ora omessa)
executable_part ::= statement_sequence
function_definition (per ora omessa)
Esempi di regole semantiche:
impossibilità di avere due identificatori con lo stesso nome nella parte dichiarativa;
un identificatore può essere utilizzato in un'istruzione solo se è stato definito/dichiarato in precedenza;
le parole chiave del linguaggio (es. float, int) e gli identificatori predefiniti (es. printf,scanf) sono riservati (Appendice C)
Esempio (Appendice A)
Programma che riceve un carattere e restituisce la codifica decimale ASCII e nel caso di lettere minuscole restituisce la maiuscola col suo codice ASCII. L'esecuzione termina quando viene letto il carattere #
Leggi carattere
Finchè non è inserito carattere terminatore esegui
Stampa codifica ASCII
Se lettera minuscola stampa maiuscola con codice ASCII
Leggi carattere
Algoritmo implementato in C
/* file del programma */
#include <stdio.h>
char C, UC;
void main()
/*else nothing*/
printf('Inserire un carattere - # per terminaren');
scanf(' %c', &C);
}
}
INGRESSO/USCITA
Tastiera- video char scanf/printf int/float memoria
#include <stdio.h> nel programma;
(int -> trascurare) printf( messaggio)
messaggio:
stringhe di caratteri tra "",
caratteri di controllo per il terminale (es. n -> salto riga),
formato di stampa e conversione: % <tipo> = u (unsigned), c (char), s (stringa di char), f (float/double formato x.y), e (float/double formato e+/- esp), d (int . )
espressione da stampare coerente col formato.
(int?) scanf (messaggio)
- formato di lettura e conversione= % <tipo>lf(double) .
- indirizzo della variabile -> & nomevariabile
Linguaggio binario 0000111100110011
Linguaggio Assembler MEM: RES 1
Linguaggio C: variabile caratterizzata da:
proprietà generali
un nome identifier
un tipo (dominio e operazioni)
!!non ha un valore iniziale (se non definito dall'utente)
proprietà dipendenti dalla posizione di definizione nel programma
modalità di allocazione e tempo di vita
Le variabili della global-declarative part sono allocate a compile time (RES) e sono deallocate a fine esecuzione del programma.
campo di validità: l'intero programma
Un tipo di dato T = <D,O> è definito da un dominio D di valori e dalle operazioni O definite sui valori.
Rappresentazione R(T) definisce:
occupazione di memoria richiesta;
codifica dei valori;
range dei valori (overflow).
La nozione di tipo permette di controllare l'uso corretto delle variabili nel programma.
Capacità di rappresentazione di un linguaggio = f(tipi di dati esprimibili)
Un tipo non disponibile in un linguaggio deve essere simulato
Più istruzioni per la sua manipolazione
TIPI SEMPLICI + COSTRUTTORI DI TIPO
TIPI DERIVATI DAL PROGRAMMATORE
f(applicazione)
Esempi:
tipo semplice: int costruttore array
tipo derivato: int A[10]
I tipi semplici sono A.D.T. ( R(T) e O nascoste)
INTERO (discreto)
D = short int, int, long int (prefisso unsigned)
R(short int) R(int) R(long int)
(1 word)
limiti: INT_MIN, INT_MAX (#include limits.h), sizeof(tipo)
O = + - * / = == > X++ .
Es. int salario=0;
REALE (denso)
D = float (precisione semplice), double (4B), long double
R(float) R(double) R(long double)
Es. 10-38 - 1038 con 6 cifre decimali per float
10-308 - 10308 con 15 cifre decimali per double
3.2 (v.fissa), 0.08, 7E+20 s 7*1020 (v.mobile)
O = vedi int (!!attenzione a ==)
Es. float salario_medio=0.0;
CARATTERE (discreto)
D = char (1B) ASCII code. Es. 'A' , 'n',
R(T) come numero intero
O = vedi int
Es. char carattere = 'a';
VOID tipo nullo
Con un tipo costruire un altro tipo
typedef old type new type;
Es. typedef int tipo_matricola;
tipo_matricola matricola_studente;
TIPO ENUMERATO (discreto)
typedef enum GiornoSettimana;
typedef enum boolean;
GiornoSettimana giorno;
boolean fine_lettura;
Come funziona
=> v1=0; vn=n (int);
non si legge e non si scrive
O = + (non utilizzare) >, < ==
init delle variabili (costanti); T inizializzare
errore di tipo nella lettura di un dato T utilizzare int in scanf
errore di overflow
in lettura T sostituire scanf
per x/0 T errore run-time T controllo operandi a priori
per altre operazioni (*, i++ . ) T controllo operandi a priori
4. errore di range applicativo T controllo dopo lettura
Es. #define A 12
#define C 'a'
#define D "stringa"
#define E 12.2 (double)
const int modello = 10;
int B, K, W;
void main()
Controllo a compile time della correttezza del tipo
Regole di compatibilità
1. Espressione con elementi (costanti, variabili) eterogenee:
conversione implicita degli operandi: minor precisione => massima precisione (char diventa int che diventa float . )
2. Assegnamento eterogeneo A = espressione:
Il tipo dell'espressione è convertito al tipo della variabile A (perdita informazione).
3. Conversione esplicita di un tipo (cast) non trattato
L'ASTRAZIONE NELLE STRUTTURE DI CONTROLLO
Linguaggio simbolico: sequenza, salto condizionato e incondizionato
programmazione non strutturata
Problemi nello sviluppo e nella manutenzione dei programmi
![]()
La programmazione strutturata
- a livello di istruzione (if, for,)
- a livello di unità (procedure, moduli).
Quali sono le strutture di controllo necessarie per scrivere un qualsiasi algoritmo?
(teorema di Bohm-Jacopini).
1. Sequenza
SequenzaIstruzioni ::= SingolaIstruzione | 1+ }
2. Istruzione condizionale doppia
if (logic_expr) SequenzaIstruzioni opt
Semantica:
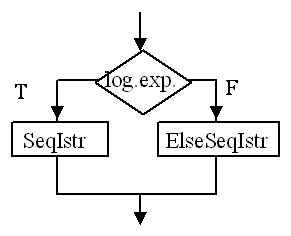
Esempi:
1. if (x >0) printf("positivo");
else
if (x<0) printf("negativo"); else printf("zero");
2. if ( x==0) z = x; else
3. if ( x==0) z = x; else w = y; z = y + 1;
4. if (reparto =1) if (salario>1000) salario++;
else . .
5. TRUE (!= 0), FALSE (=0) (if x=0 equivale a if x)
6. side effects: if (x=y)
while (logic_expr) SequenzaIstruzioni
Semantica:
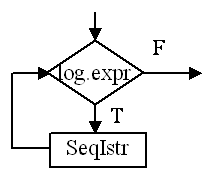
Osservazioni
logic_expr deve essere calcolabile prima dell'esecuzione del ciclo.
numero iterazioni
Esempio:
Problema:
Leggere da terminale una sequenza di punteggi terminata dal valore
-99 e stampare la somma dei punteggi.
Algoritmo:
Definisci valore sentinella
init sum a 0
leggi primo punteggio
while punteggio != sentinella
stampa sum
Programma C:
#include <stdio.h>
#define sentinella -99
int sum = 0, punteggio;
void main()
printf("nSomma = %d", sum);
Errori comuni:
omettere inizializzazione di sum
violazione osservazione 1 e somma di "sentinella" a sum.
init sum a 0
while punteggio != sentinella
dimenticare
while (punteggio != sentinella)
sum = sum + punteggio;
printf("prossimo punteggio o %d per uscire ", sentinella);
.
/*end while*/
provare con primo punteggio: 10 10<return> (doppia lettura)
provare con 7o (loop infinito)
4. Istruzione condizionale multipla
switch (expression
opt
Osservazioni:
expression = valore i T esecuzione case valore i + case che seguono
expression tutti i valori T esecuzione case di default se esiste, altrimenti no operation
5. Ciclo a condizione finale
do SequenzaIstruzioni while (logic_expr);
Semantica:

Osservazioni:
logic_expr deve essere calcolabile dopo l'esecuzione del ciclo.
numero iterazioni
Esempio:
do
while (letter >='a' && letter <='h');
6. Ciclo for
for (expression1; expression2; expression3) opt
Semantica:
expression1;
while (expression2)
opt
expression3
Esempio:
for (i=1; i<=100; i++)
Osservazioni:
for (a=1; v!='0' ; i++);
for (; ;)y++; loop infinito
for (i=1; i<=100; i++); ciclo vuoto
7. Le istruzioni di salto
break (si applica all'istruzione switch, for, while, do while)
salto strutturato alla prima istruzione che segue l'istruzione
continue (si applica a for, while, do while)
salto strutturato alla prossima iterazione del ciclo
goto X
X: . . !!dimenticare
I tipi definiti dall'utente
Aggregati di oggetti elementari e non.
TIPI SEMPLICI + COSTRUTTORI DI TIPO
TIPI DERIVATI DAL PROGRAMMATORE
f(applicazione)
Operazioni:
predefinite: operazioni dei costruttori e dei tipi semplici;
applicative: operazioni definite dal progettista dell'applicazione (sottoprogrammi).
I costruttori
FINITE MAPPING (costruttore ARRAY)
Aggregato ordinato di elementi dello stesso tipo;
dimensione fissa; memoria centrale
accesso agli elementi posizionale.
CARTESIAN PRODUCT (costruttore RECORD)
Aggregato di elementi che possono essere di tipo diverso;
dimensione fissa; memoria centrale
accesso agli elementi per nome .
RECURSIVE (costruttore PUNTATORE)
Aggregato di elementi dello stesso tipo costruito ammettendo che un tipo possa contenere componenti dello stesso tipo; memoria centrale
dimensione arbitraria;
accesso sequenziale agli elementi.
SEQUENCE (non esiste costruttore)
Aggregato ordinato di elementi dello stesso tipo;
dimensione arbitraria; memoria secondaria
accesso sequenziale agli elementi
Es. #define DIM 10
int V[DIM], S[DIM];
int V[DIM] = ;
typedef int tipovettore[DIM];
tipovettore V,S;
Allocazione memoria
- V: RES 10 (V s indirizzo primo elemento)
0 <= posizione elemento <= (DIM -1)
accesso elemento V[3]
scanf e printf sul singolo elemento
Accesso globale
- V = S; non permesso
Esempio:
#include <stdio.h>
#define DIM 10
int V[DIM]; int i;
void main()
Osservazione:
C non controlla il superamento dei confini dell'array
Esempio:
#include<stdio.h>
char d[80]; int i; char val;
void main()
Strutture particolari
matrice typedef int A[10];
A B[ 20]; s int B [20][10];
- le stringhe sono array di char che terminano con '0' (NULL) e sono gestite con le funzioni di <string.h>, %s in scanf e printf.
1) typedef struct vet;
vet V,Z;
2) struct vet ;
struct vet V,Z;
3) struct V,Z;
Allocazione memoria V.A: RES 1
V.B: RES 1
Accesso al singolo elemento
V.A = 2;
scanf e printf sul singolo elemento
Accesso globale
- V = Z; permesso
Esempi:
typedef char stringa[20];
typedef struct
TipoStudente;
Tipostudente Lista[100];
Tipostudente Studente;
printf("cognome = %s",Studente.cognome);
printf("cognome = %s",Lista[i].cognome);
printf("matricola = %d",Lista[i].matricola);
L'ALLOCAZIONE STATICA DEGLI ARRAY
La dimensione di un array è fissata nella definizione
Cosa accade se l'applicazione deve gestire sequenze di lunghezza variabile?
lunghezza della sequenza supera la dimensione dell'array
prevedere controllo sulla lunghezza
cambiare il codice sorgente
lunghezza della sequenza variabile nei limiti
stabilire una dimensione massima per la definizione dell'array;
definire un meccanismo di gestione della dinamicità
Modello basato sulla contiguità fisica
Soluzione 1: valori come delimitatori
|
|
MAX |
|
|
|
| |
|
|
valore speciale |
|
typedef struct
TipoStudente;
Tipostudente Lista[100];
il valore speciale non DEVE mai avere un significato applicativo durante tutta la vita dell'applicazione.
Soluzione 2: variabile di supporto.
|
|
MAX |
|
|||
|
|
? ? ? ? ? ? ? ? ? ? | ||||
|
ultimo |
|
| |||
1. typedef struct
TipoStudente;
Tipostudente Lista[100];
int ultimo;
2. typedef struct
TipoStudente;
typedef struct
Vettore;
Vettore ListaStudenti;
Modello basato sulla distinzione logica
|
|
|
|
|
|
|
|
|
|
|
| |||||||||||||
|
T |
F |
F |
T |
T |
T |
F |
T |
F |
T |
T | |||||||||||||
|
occupato |
|
|
|
libero |
|
|
|
|
|
|
|
|
|||||||||||
typedef enum boolean;
typedef struct
Tipostudente;
Tipostudente Lista[100];
Ricordare di:
inizializzare i valori di supporto (valore speciale, ultimo, libero) prima dell'utilizzo dell'array e di mantenere la congruenza nelle operazioni di aggiornamento della struttura;
controllare i confini dell'array prima di indirizzare un elemento;
controllare le situazioni limite: array pieno e array vuoto.
Array e applicazioni:
applicazioni in cui sembra servire un array;
Leggere sequenza di N valori 0,1 dal terminale e visualizzare il numero di 1 presenti nella sequenza
(NO)
Leggere sequenza di valori 0,1 da terminale e visualizzare la sequenza in complemento a 1; la sequenza è di lunghezza arbitraria con il valore 2 come terminatore.
NO se il complemento è visualizzato direttamente dopo la lettura di ogni singolo valore.
SI se il complemento è visualizzato dopo l'acquisizione dell'intera sequenza.
applicazione con vettore completo;
vettori matematici
applicazione con vettore a dimensione dinamica richiesta a priori o determinata dalla lettura e gestione dati
- pila/stack (politica LIFO)
- coda (politica FIFO)
- sequenza numerica (può essere nota a priori)
- archivio dati
Accesso alle variabili via nome e via indirizzo
VARIABILI SEMPLICI
int Norm;
int *Pointer1=NULL, *Pointer2;
float *Pointer3;
|
Norm Ind1 |
|
Pointer1 Ind2 |
NULL |
|
|
|
|
|
Pointer2 Ind3 |
|
Pointer3 Ind4 |
|
Norm = 4;
|
Norm Ind1 |
|
Pointer1 Ind2 |
NULL |
|
|
|
|
|
Pointer2 Ind3 |
|
Pointer3 Ind4 |
|
Pointer1 = &Norm;
|
Norm Ind1 |
|
Pointer1 Ind2 |
Ind1 |
|
|
|
|
|
Pointer2 Ind3 |
|
Pointer3 Ind4 |
|
Pointer2 = Pointer1;
|
Norm Ind1 |
|
Pointer1 Ind2 |
Ind1 |
|
|
|
|
|
Pointer2 Ind3 |
Ind1 |
Pointer3 Ind4 |
|
*Pointer1 = 5; s Num = 5
|
Norm Ind1 |
|
Pointer1 Ind2 |
Ind1 |
|
|
|
|
|
Pointer2 Ind3 |
Ind1 |
Pointer3 Ind4 |
|
printf("%d %d %d", Norm, *Pointer1, *Pointer2); T
Pointer3 = Pointer1; warning a compile time
int **PointerToPointer;
PointerToPointer = &Pointer1;
|
Norm Ind1 |
|
Pointer1 Ind2 |
Ind1 |
PointerToPointer Ind5 |
Ind2 |
|
Pointer2 Ind3 |
Ind1 |
Pointer3 Ind4 |
|
**PointerToPointer = 10;
|
Norm Ind1 |
|
Pointer1 Ind2 |
Ind1 |
PointerToPointer Ind5 |
Ind2 |
|
Pointer2 Ind3 |
Ind1 |
Pointer3 Ind4 |
|
VARIABILI STRUTTURATE
IL VETTORE
typedef int A[10];
A vet1;
A *P1;
int (*Q1) [10];
P1 =&vet1; s Q1 = &vet1;
|
vet1[0] |
vet1[1] |
. . |
vet1[9] |
vet1 |
P1 |
|
|
Q1 |
(*P1)[1] =33; s vet1[1] = 33;
|
vet1[0] |
vet1[1]=33 |
|
vet1[9] |
vet1 |
P1 |
|
|
Q1 |
IL RECORD
typedef struct miotipo;
miotipo rec;
miotipo *R;
R = &rec; rappresenta anche l'indirizzo del primo elemento
|
Rec.a |
rec.b |
rec |
R |
(*R).a = 55; s R ->a = 55;
|
rec.a = 55 |
rec.b |
rec |
R |
IL VETTORE: una variante
typedef int A[10];
A vet2;
int *P2;
P2 =vet2; s P2 = &vet2[0];
|
vet2[0] |
vet2[1] |
|
Vet2[9] |
vet2 |
|
|
P2 |
vet2[0] = 45; s *P2 = 45;
|
vet2[0]= 45 |
vet2[1] |
.. |
vet2[9] |
vet2 |
|
|
P2 |
P2 = &vet2[7];
B[7] = 10; s *P2 = 10; (P2 assume valori diversi nel
tempo)
L'aritmetica dei puntatori
P2 = vet2; P2 punta al primo elemento di vet2
P2 = P2 + 1 T indirizzo(P2) + sizeof(int) s &vet2[1]
P2 = vet2;
*(P2+1) s vet2[1]
P2 = vet2;
for (i=0; i<=9; i++)
stampa:
P2 = vet2;
P2++;
P2 - vet2 è uguale a 1 indipendentemente dal tipo
Osservazione 1: puntatore a vettore
typedef int A[10];
A vet1;
A *P1;
P1 =&vet1;
P1 ++ T indirizzo(P1) + sizeof(A)
Osservazione 2: interpretazione definizioni
int *p[5] => array di 5 pointer to int
int (*p) [5] => pointer to array di 5 int
Un sottoprogramma isola una porzione di codice
E permette:
scomposizione problemi
riuso del codice
definizione di nuovi tipi (Abstract Data Types)
Esempio 1:
miotipo archivio[MAX];
int scelta; enum fine=FALSE;
void main()
}
I sottoprogrammi funzionali e procedurali
(procedure)
Schema base di un programma.
program ::= directive_part opt
void main ()
directive_part ::= ..#include identifier | #define identifier value
global_declarative_part ::= declarative_part;
function_definition::=type identifier opt)
function_declarative_part ::= declarative_part;
declarative_part ::=constant_declarations | type_declarations |
variable_declarations
executable_part ::= statement_sequence
main è una funzione;
una funzione riceve dei valori attraverso i parametri e restituisce un valore (ecc. main);
una funzione (anche main) possiede dichiarazioni locali:
regole delle dichiarazioni globali;
una funzione possiede istruzioni (main);
una funzione deve contenere return (expression):
indica il termine dell'esecuzione della funzione;
indica il valore da ritornare al programma chiamante;
una funzione è invocata nei contesti dove appare expression:
function_call::= identifier (opt)
una funzione non può definire un'altra funzione innestata (vedi local_declarative_part)
Esempio 2:
#include <stdio.h>
int X, Y, Z;
int sum(int parameter1, int parameter2)
void main ()
Esecuzione:
|
|
area dati globali X Y Z ? ? ? |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
3 |
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Dati locali a main |
|
Dati locali sum Risultato ? Ret_adr ? parameter1 ? parameter2 ? temp |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Macchina main . scanf("%d",X); . scanf("%d",Y); Z = sum(X,Y); Printf( . .); |
- |
Macchina sum int sum(int parameter1, int parameter2) | MOV X, parameter1 MOV temp, Risultato MOV Y, parameter2 MOV ret_adr, PC MOV Rit, Ret_adr Next fetch MOV indirizzo (prima istruzione sum), PC Next fetch Rit:MOV Risultato, Z I parametriI parametri formali definiscono l'interfaccia della funzione tiporis nomefunction([tipo1 nome1, . tipon nomen]op); numero parametri formali: - non limitato; - uguale al numero di quelli attuali in ogni attivazione; tipo dei parametri formali: identificatore del tipo e NON la sua definizione e può essere un tipo base, una struct, un puntatore (NO array); corrispondenza tra parametro formale e attuale: posizionale; ogni coppia parametro attuale/formale rispetta le regole di compatibilità e di conversione definite per le espressioni; modalità di passaggio parametri: per valore: la funzione riceve un valore, lo può modificare e utilizzare; il valore ricevuto non è più restituito; il parametro attuale può essere una variabile, costante o espressione; la funzione ritorna un risultato; tipo del risultato: tipo base, struct, puntatore, void (NO array). I sottoprogrammi procedurali Una funzione invocata come un'istruzione si chiama proceduraEsempio: Insert(); l'invocazione procedurale implica la perdita del valore prodotto dalla funzione; utilizzo del tipo void se non interessa il valore ritornato (es. void main()..) una procedura può evitare il return (la procedura termina quando incontra la "}" che chiude la funzione. Passaggio parametri per indirizzo simulato parametro formale: tipo puntatore (*P) al tipo di struttura ricevuta; parametro attuale di tipo indirizzo (&) alla struttura dati passata; obbligatoria per gli array; utilizzata anche per risparmiare memoria nel passaggio di una struttura dati di grandi dimensioni. Esempio 3: #include <stdio.h> typedef int Tarray[8]; Tarray A; void S1(Tarray a) s void S1(int a[]) /* primo elemento void S2(int *a) void main() esecuzione:
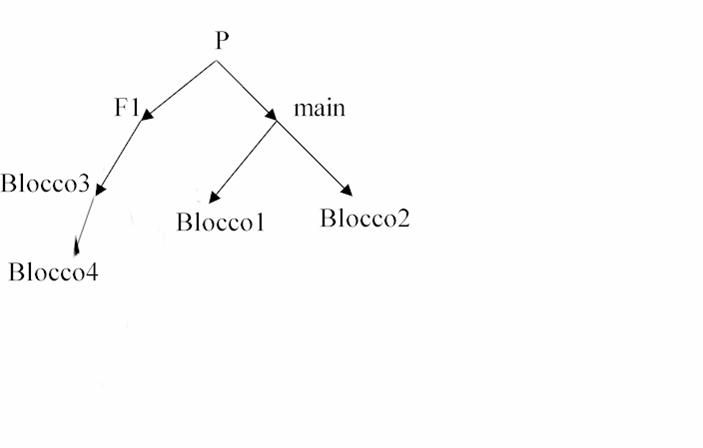
inizio stampa Regole di visibilità degli identificatori Concetto di blocco Block ::= block_declarative_part ::= declarative_part una funzione è un blocco speciale con nome e parametri; un blocco può dichiarare un altro blocco all'interno una funzione può contenere più blocchi Esempio 4: #include <stdio.h> typedef struct T; void main() void F1(int x) } x=3; /*istruzione 1*/ T=4; /*istruzione 2*/ J=5; /*istruzione 3*/ F1(4); /*istruzione 4*/ } Definizioni: identificatori di un programma s nomi assegnati a variabili, costanti, tipi e funzioni; identificatori globali sidentificatori definiti nella global_declarative_part; identificatori locali di una funzione s identificatori definiti nella function_declarative_part e nei parametri formali; identificatori locali di un blocco s identificatori definiti nella block_declarative_part; Campo di validità di un identificatore (scope) Istruzioni del programma nelle quali un identificatore è visibile e manipolabile. Campo di validità "teorico" (scope rules): il blocco coincide con il campo di validità dei suoi identificatori locali; la funzione coincide con il campo di validità dei suoi identificatori locali; se un blocco/funzione contiene altri blocchi, il campo di validità degli identificatori del blocco/funzione più esterno si estende ai blocchi innestati; il campo di validità degli identificatori globali coincide con l'intero programma. Ancora l'esempio 4. La rappresentazione gerarchica delle dichiarazioni (derivata in modo statico)
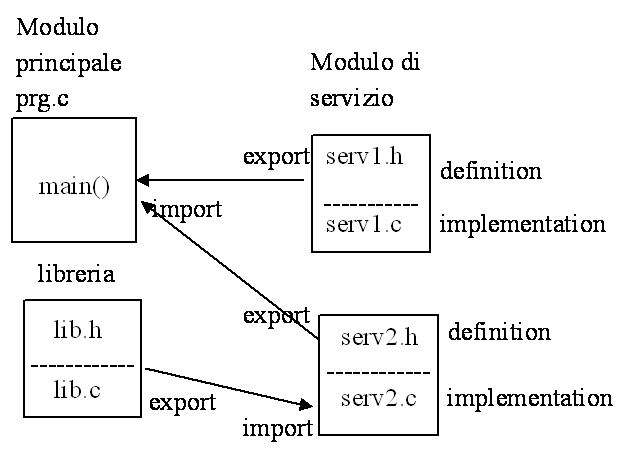
programma T, F1, main il programma main a main, blocco1,blocco2 blocco1 b blocco1 blocco2 c blocco2 F1 x,d F1, blocco3, blocco4 blocco3 e blocco3, blocco4 blocco4 f blocco4 Domanda: le istruzioni della funzione F1sono corrette? SI locale a F1 2. NO improper use of typedef 3. NO undefined symbol SI globale Conflitto tra campi di validità /*Program*/ int i; void main() Algoritmo di risoluzione dei conflitti (campo di validità reale): Dato un identificatore ID presente in un'istruzione I: si cerca l'identificatore ID tra quelli locali al blocco/funzione S a cui appartiene l'istruzione I; se non lo trova e siamo in un blocco, allora cerca negli identificatori locali al blocco/funzione nel quale è stato dichiarato il blocco S; la navigazione può proseguire sino agli identificatori locali di una funzione; se non lo trova e siamo in una funzione, allora cerca negli identificatori globali; la ricerca termina con successo quando l'identificatore è individuato o con errore di compilazione se non è trovato. Allocazione e tempo di vita delle variabili le variabili globali (statiche): allocate a inizio esecuzione programma; tempo di vita s tempo di esecuzione del programma; le variabili locali di un blocco/funzione (automatiche - RDA): allocate a inizio esecuzione del blocco/funzione; tempo di vita s tempo di esecuzione del blocco/funzione - inizializzazione ad ogni invocazione; - RDA allocato nello stack. Funzioni ed effetti collaterali Esempio 5: /* P */ int b,c; int sum(int x) void main() Esempio 6 /* P */ int b,c; int sum(int x) void main() PRINCIPIO Una funzione DEVE utilizzare SOLO variabili e costanti dichiarate nei parametri o nella function_declarative_part. Sviluppo strutturato e incrementale di un'applicazione Il problema Memorizzare i risultati di un test sostenuto da N studenti e visualizzare la media dei punteggi ottenuti dagli studenti suddivisi nelle tre classi di appartenenza (prima, seconda,terza). Predisporre inoltre una operazione che permetta di ordinare i dati in base al numero di matricola. Il programma contiene un menù con le seguenti voci: 1 per memorizzare i dati, 2 per la media, 3 per terminare l'esecuzione. Impostazione progetto delle strutture dati globali; suddivizione del problema in sottoproblemi e identificazione dei componenti del programma; raffinamenti incrementali. Lo schema del programma: una struttura dati globale; una funzione per il caricamento dati; una funzione per il calcolo della media; una funzione per l'ordinamento; la funzione main col menù. Alcuni suggerimenti semplicità, chiarezza, niente trucchi (indice di ingenuità), massimizzare l'uso di parametri e dati locali; buona documentazione: commenti all'inizio del programma per identificare nome del programmatore, data e versione del programma (vers. x.y), per descrivere obiettivi, strutture dati globali, algoritmi, funzioni utilizzate; commenti nelle funzioni per descrivere obiettivi, algoritmi e strutture dati; stile: nomi significativi per gli identificatori (ad esempio: ImportoSalario); separare le istruzioni su linee diverse; utilizzare l'indentazione; spazi tra operandi di istruzioni/espressioni, linee bianche di separazione tra segmenti diversi di codice. La struttura dati: #define N 100 /*max numero di studenti */ typedef struct T_studente; typedef T_studente T_arc[N]; T_arc archivio; int ultimo; /*gestione dinamica del vettore archivio*/ La funzione main (struttura di base): /* Program: . Responsabile: . data: . vers. #include <stdio.h> typedef enum boolean; void main() } Sviluppo funzioni come stubs: void MemorizzaDati(T_studente *s, int *u) int CalcoloMedia(T_studente *s, int u), void Ordina(T_studente *s, int u), Raffinamento funzioni: void MemorizzaDati(T_studente *s, int *u, int MAX) } while (!ok); /*2. per ogni studente legge i dati*/ for (i=0;i<quanti;i++) /*3. restituisce il vettore e l'indice dell'ultimo elemento caricato *u = quanti -l; float CalcoloMedia(T_studente *s, int u) La verifica dell'applicazione (funzionale o prestazionale?) Verifica funzionale: Verificare le singole funzioni del programma; un programma non sempre utilizza tutte le funzionalità offerte (ad esempio, la funzione Ordina); il test: Si procede al test supportati da eventuale funzione di stampa; /*Procedura di test*/ void Stampa (T_studente *s, int u) identificare il tipo di ingresso da verificare: grandi o piccoli insiemi, valori limite, dati errati, particolari ordinamenti dei dati; ad esempio, inserire 0, N e N+1 elementi nel vettore, errori di tipo, violazione di range o overflow in lettura); - identificare le sequenze di attivazione delle procedure (ordinamento sequenziale o casuale nelle menù driven); - identificare il tratto critico da sottoporre a verifica (ad esempio, calcoli nei quali si può generare overflow i++, N/0); identificare le variabili da verificare, copertura delle istruzioni; - definire lo strumento di controllo (debugger o istruzioni di write). LA PROGRAMMAZIONE IN GRANDELo sviluppo di sistemi di programmi di grandi dimensioni, sviluppati da molte persone e che continuano a evolvere nel tempo Ciclo di vita di un'applicazione studio di fattibilità (costi/benefici alternative); raccolta/analisi requisiti; progettazione e realizzazione dei programmi); verifica (test di sistema, alfa test: uso reale nell'azienda produttrice, beta test: uso reale da clienti particolari); manutenzione: correttiva (20%) ed evolutiva (80%) - può superare il 50% dei costi complessivi. La progettazione e la realizzazione si pone degli obiettivi di qualità esterne del prodotto (utente): correttezza efficienza (risorse e tempo) --> valutazione complessità robustezza ai malfunzionamenti usabilità dell'interfaccia interne del prodotto (produttore): riusabilità in future applicazioni modularità estendibilità per future esigenze portabilità su piattaforme diverse compatibilità con programmi di terze parti leggibilità intesa come correlazione del codice con le scelte effettuate completezza ed efficacia della documentazione adotta dei principi: distinzione tra livello concettuale (cosa voglio) e livello realizzativo (come lo realizzo); astrazione (evidenziare gli aspetti rilevanti tralasciando i particolari); decomposizione (strutturazione di un sistema in parti - top/down, bottom/up - stabilendo le relazioni tra di esse). sceglie le tecniche/strumenti opportuni: tecniche di programmazione (programmazione strutturata, ricorsiva, ad oggetti); modularizzazione; tecniche di progettazione di algoritmi e strutture dati. i linguaggi per la programmazione (C, C++, Java, ). La modularizzazione Programmi composti da parti indipendenti (moduli) e interagenti tramite opportune interfacce. Obiettivo: sviluppo di un programma l'architettura globale (decomposizione programma in moduli con relative interconnessioni) realizzazione del singolo modulo (raffinamento incrementale, sviluppo strutturato). Effetti: correttezza di un programma ricondotta alla correttezza dei singoli moduli; integrazione naturale con moduli precedentemente realizzati; facilità nel riuso; compilazione separata. Criteri di modularizzazione: coesione: massimizzare l'uniformità e l'omogeneità dei componenti incapsulati in un modulo (strutture dati con le proprie funzioni); information hiding: esportare da un modulo solo quanto necessario (massimizzare dati e funzioni locali); accoppiamento: minimizzare il grado di interrelazione tra oggetti di moduli diversi (limitare l'esportazione di variabili globali); l'interfacciamento esplicito: esplicitare le modalità di comunicazione tra i moduli. Criteri aggiuntivi: peso equivalente dei moduli definiti; incapsulare in moduli parti dipendenti dall'hardware e/o software di base oppure legate a frequenti o previsti cambiamenti delle esigenze (approccio per cambiamento); incapsulare in moduli parti che potranno trovare un riutilizzo futuro: generalizzazione di funzioni, utilizzo dell'astrazione (approccio per il riuso). Tipi di modularizzazionefunzionale: insieme omogeneo di funzionalità rispetto ad un obiettivo (es. funzioni di stampa per più dispositivi, manipolazione stringhe, funzioni di conversione); per oggetto: gestione di un particolare oggetto offrendo all'esterno un insieme di operazioni per utilizzare correttamente l'oggetto, nascondendo le porzioni dello stato interno dell'oggetto che non hanno rilevanza rispetto ai servizi offerti (es. funzioni gestione di un video o di un particolare archivio); per tipo astratto: offre un tipo sul quale è possibile definire oggetti (istanze) e delle operazioni per manipolare le istanze del tipo. Nasconde la struttura del tipo (es. gestione file). La modularizzazione in C Limiti della nozione di functionla testata della function non definisce l'interfaccia: identificatori impliciti indipendenza reciproca limitata: monomodulo Dal programma monomodulare al programma composto da più file: un file è principale e gli altri di servizio.
ciclicità di importazione non permessa.
Realizzazione di un modulo/FILE di servizio un file di servizio è costruito con le regole descritte per il file principale; nei file di servizio non è possibile distinguere l'interfaccia dall'implementazione (definition e implementation module) Import di variabili, variabili costanti e funzioni 1. Realizzazione senza header file. Nel file xx.c che deve importare da altri file inserire le dichiarazioni: 1. extern const int MAX; per import di una costante variabile 2. extern int V[MAX]; per import di una variabile 3. extern int f(int *p); per import di una funzione - non si precisa da quale file importare - controllo tipologia a compile time - 1. e 2. non allocano spazio e 3. non riporta il contenuto Esempio; /*file export.c*/ const int MAX =3; int V[10]=; int f(int *p) /*file import.c*/ #include <stdio.h> extern const int MAX; extern int V[10]; extern int f(int *p); void main() 2. Realizzazione con header file - file di interfaccia (estensione .h) con le dichiarazioni di esportazione; - file di implementazione (estensione .c) con il codice - include del file .h nei file utilizzatori e nel file .c - espansione macro Esempio: /*file export.h*/ extern const int MAX; extern int V[10]; extern int f(int *p); /* file export.c*/ #include 'export.h' /* per la congruenza*/ const int MAX =3; int V[10] =; int f(int *p) /*file import.c*/ #include <stdio.h> #include 'export.h' void main() 3. Una variante nel file.h Esempio: /*file export.h*/ #if defined export const int MAX; int V[10] =; extern int f(int *p); #else extern const int MAX; extern int V[10]; extern int f(int *p); #endif /* file export.c*/ #define export #include 'export.h' /* per la congruenza*/ int f(int *p) /*file import.c*/ #include <stdio.h> #include 'export.h' void main() 4. le regole sugli identificatori Unione degli identificatori globali di tutti i file del programma costituiscono gli identificatori globali del programma. => due identificatori globali in file diversi non possono avere lo stesso nome (main()); il campo di validità di un identificatore globale ID coincide col file che lo definisce e con tutti i file nei quali è dichiarato (extern ID); => tutti gli identificatori definiti in un file sono automaticamente esportati. un identificatore da non esportare va dichiarato come static => identificatore globale al solo file nel quale è definito. Esempio: /* file export.c*/ #define export #include 'export.h' /* per la congruenza*/ int f(int *p) static void stampa(int *p); Le classi di memoria per variabili (incluso variabili costanti)
il tempo di vita delle variabili globali (anche static) coincide col tempo di esecuzione dell'intero programma . Import di costanti e tipi (typedef, define, tipi) Non esiste la nozione di identificatore globale del programma e di dichiarazione, ma solo di identificatore globale del file => le definizioni valgono solo per il file nel quale sono riportate e non sono esportate 1. Simulazione interfaccia con header file /*file export1.h*/ #define MAX 10 struct C ; typedef struct C D[MAX]; extern D vettore; extern void f(struct C *p); /*file export1.c*/ #include 'export1.h' #include <stdio.h> D vettore void f(struct C *p); /*file import1.c*/ #include <stdio.h> #include 'export1.h' void main() Osservazioni: Violazione information hiding; Il C non supporta il tipo di dato astratto; La definizione di un identificatore è duplicata (file export e file import); Problema: /*file export.c*/ struct C ; struct C var1 = ; /*file import.c*/ struct C ; extern struct C var1; main(); CATENA DI PROGRAMMAZIONE Problema analisi e progettazione algoritmo risolvente EDITOR file .c file .c file.h(codice sorgente)COMPILATORE codice oggetto codice oggetto codice oggetto (librerie) __________ ________________ COLLEGATORE codice eseguibile LA MODULARIZZAZIONE PER OGGETTO
Esempio di modularizzazione per oggetto /*file export2.h*/ extern void insert (); extern void visualizza(); /*file export2.c*/ #include <stdlib.h> #include 'export2.h' struct T_elem ; typedef struct T_elem elemento; static elemento *lista=NULL; static elemento *creael () return(elem); } void visualizza() } void insert () } /*file import2.c*/ #include <stdio.h> #include 'export2.h' void main() Esempio di modularizzazione per astrazione /*file export3.h*/ struct T_elem ; typedef struct T_elem elemento; extern elemento *insert (elemento *lista); extern void visualizza(elemento *lista); /*file export3.c*/ #include <stdlib.h> #include 'export3.h' static elemento *creael () return(elem); } void visualizza(elemento *lista) elemento *insert (elemento *lista) return(lista); } /*file import3.c*/ #include <stdio.h> #include 'export3.h' static elemento *lista=NULL; void main() Verso la programmazione ad oggetti Definire due tipi di dato astratto linea e poligono. Le operazioni disponibili sono: - Crea: riceve le coordinate e genera un oggetto del tipo associato. - Intersect: ritorna TRUE se una linea interseca un poligono. boolean intersect (poligono x, linea t); I FILELa gerarchia della memoria
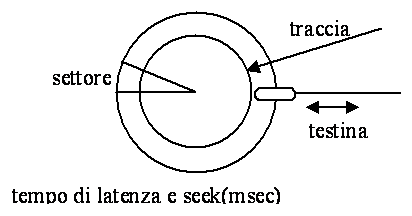
Nastro: struttura sequenziale
bot <------> eot Disco: struttura non sequenziale
La memoria centrale come sequenza di parole fisiche. La memoria secondaria come sequenza di contenitori di dati, chiamati file. Il file è una struttura dati persistente di arbitraria dimensione contenente dati correlati di tipo strutturato o di tipo testo. Struttura e metodi di accesso struttura sequenziale; accesso sequenziale (scansione degli elementi) e diretto (accesso ad un elemento tramite la sua posizione nel file). Modalità di accesso memoria centrale: diretto A[I], X.a memoria di massa indiretto
Concetto di stato esistente e vuoto
I FILE in C Le strutture dati persistenti, e in generale i dispositivi di I/O, sono gestiti sono gestiti da opportune librerie fornite con il linguaggio Le funzionalità del modulo <stdio> Tipi di file file di testo; file binari (occupazione e portabilità); Tipo di accesso sequenziale -----> <------> diretto
1 .. Il descrittore del file
La tabella dei file aperti (per utente, per il sistema) stdin descrittore 1 tastiera scanf, . stdout descrittore 2 video printf, . stderror descrittore 3 video fd1 descrittore 4 file fd2 descrittore 5 file Definizioni e funzioni C preliminari #include <stdio.h> FILE *fp; descrittore del file fp = fopen(filename, mode); filename: stringa tra " " o pointer to string mode operazione tipo operazione ammessa file eseguita ------ -------- ---- ----------- "r" lettura testo bof su file esistente "w" scrittura testo bof dopo (rewrite o creazione) "a" append testo eof dopo (posizion. o creazione) "rb" lettura binario bof come sopra "wb" scrittura binario bof " "ab" append binario eof " varianti: "r+" "rb+" lettura e scrittura "w+" "wb+" scrittura e lettura "a+" "ab+" append e lettura fp =NULL se esito è negativo concorrenza nell'uso dei file int fclose(fp) esito positivo T fp=NULL; return (0) esito negativo T return(EOF) int remove(filename); int rename(oldname,newname); Indicatori di errore (riportano l'esito dell'ultima read/write) int=feof(fp); eof T return (!0) non eof T return(0) int ferror (fp); errore T return (!0) Es.: write dopo close corretto T return(0) int clearerr(fp); - indicatori di error e eof T Funzioni C di manipolazione dei dati
Manipolazione file testo formattataint fscanf(fp, stringa controllo, adr(variabili)); lettura con conversione implicita; legge a partire dalla posizione corrente; sposta la posizione corrente del numero di caratteri letti; corretta T return(numero elementi letti >0, escluso eof) errore T return(<0) T controllo se feof o ferror int fprintf(*fp, stringacontrollo, variabili); scrittura con conversione implicita; scrive a partire dalla posizione corrente; sposta la posizione corrente del numero di caratteri scritti corretta T return(numero elementi scritti errore T return(<0) Esempio: /*programma manipolazione formattata senza controllo errori*/ file.txt
#include <stdio.h> #include <string.h> typedef struct T_persona; FILE *fp; char filename[20]='file.txt'; T_persona p1; void main() else if ((fp = fopen(filename, 'r')) == NULL) else Manipolazione file testo per carattereint getc(fp); macro int fgetc(fp); funzione legge a partire dalla posizione corrente; sposta la posizione corrente di un carattere; corretta T return(codifica numerica ASCII del carattere letto) errore T return(EOF) T ferror, feof int putc(c, fp); macro int fputc(c, fp); funzione scrive a partire dalla posizione corrente; sposta la posizione corrente di un carattere; scrive il carattere c espresso come numero; - corretta T return(carattere scritto) - errore T return(EOF) Manipolazione file testo per stringhechar *fgets(char *str, int n, fp); Lettura di n-l chars (se non incontra eof, <ret>) dalla posizione corrente del file e li carica in str con 0. sposta la posizione corrente di n caratteri; Corretta T return (str) Errata T return(NULL) T ferror, feof char *gets (char *str); per stdin int *fputs(char *str, fp); scrive str sino a 0 (escluso) sul file a partire dalla posizione corrente sposta la posizione corrente di n caratteri; corretta T return(0) errata T return(EOF) int *gets (char *str); per stdout Manipolazione file binarioint=fread(adr(var), sizeof(elemento), numelementi, fp) legge a partire dalla posizione corrente; sposta la posizione corrente di numero bytes letti; return (numelementi letti) numelementi letti < numelementi T errore T feof, ferror) int=fwrite(adr(var), sizeof(elemento), numelementi, fp) scrive a partire dalla posizione corrente; sposta la posizione corrente di numero bytes scritti; return (numelementi scritti) numelementi scritti < numelementi T errore) Accesso direttoint fseek(fp, long offset, int origine) origine = SEEK_SET T posizione = bof + offset SEEK_CUR T posizione = pos.corr. + offset SEEK_END T posizione = eof + offset corretta T return(0) errore T return(<0) long ftell(fp) corretta T return (posizione corrente) errore T return(<0) rewind (fp); - posizione = bof Esempio: /*Programma che genera il file itinerari*/ #include <stdio.h> #include <string.h> typedef struct T_record; T_record record; FILE *id; void main() fclose(id); /*Programma per legger un itinerario*/ #include <stdio.h> #include <string.h> typedef struct T_record; typedef enum BOOLEAN; T_record record; int pos; FILE *id; char citta[30]; BOOLEAN trovato= false; void main() else fclose(id); } La gestione del bufferint fflush(fp) forza buffer write - write ->buffer ->disco File e applicazioniLe applicazioni: memorizzano i dati in file in base a: - struttura logica dei dati; - tipo di operazioni previste; definiscono strutture di memoria centrale di supporto. I gestori di sistema devono salvare periodicamente i file (backup).
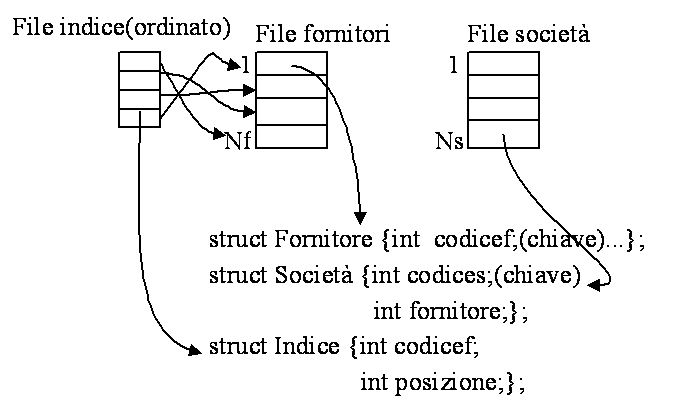
Gestione del file: file passivo: le strutture dati persistenti sono lette interamente all'inizio dell'esecuzione dell'applicazione e riscritte interamente alla fine dell'esecuzione; durante l'esecuzione il file non è utilizzato. file attivo: l'applicazione accede ai dati durante l'esecuzione. Esempi: Ipotesi: ininfluente il costo della manipolazione in memoria centrale. Esempio 1: Applicazione per la gestione di due archivi: fornitori e società; una società può avere un solo fornitore, mentre un fornitore può fornire più società. Ipotesi: file come struttura attiva dell'applicazione. Struttura dei file:
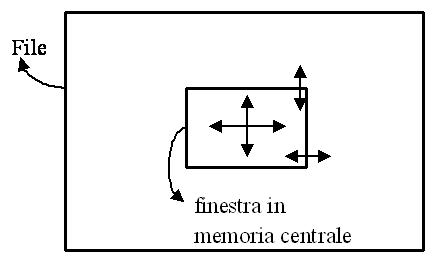
Operazioni e loro valutazione: 1. Trovare il fornitore con codice = xx; a) Algoritmo di scansione sequenziale: typedef enum BOOLEAN; typedef struct T_FORN; T_FORN fornitore; BOOLEAN fine = false; LeggiForn(file, fornitore); while (!fine && !eof(file)) LeggiForn(file, fornitore); } costo (equiprobabilità): (Nf / 2)*sizeof(fornitore); costo (ricerca su valore non chiave): Nf * sizeof(fornitore) b) Algoritmo di scansione sequenziale via indice: typedef enum BOOLEAN; typedef struct T_FORN; typedef struct T_INDEX; T_FORN fornitore; BOOLEAN fine = false; T_INDEX indice; LeggiIndex(fileindice, indice); while (!fine && !eof(fileindice)) LeggiForn(fileindice, indice); } } costo (equiprobabilità): (Nf / 2)*sizeof(indice) + 1* sizeof(fornitore) raffinamenti possibili: ricerca binaria su indice ordinato, indice in memoria. 2. Stampare i dati di ogni fornitore inclusi i dati delle società fornite: a) Algoritmo di scansione sequenziale dei due file con memoria minima: typedef struct T_FORN; typedef struct T_COMP; T_FORN fornitore; T_COMP società; LeggiForn(filefornitore, fornitore); while (!eof(filefornitore)) LeggiForn(filefornitore, fornitore); costo: Nf * sizeof(fornitore) + Nf * Ns * sizeof(societa) b) Algoritmo di scansione sequenziale dei due file con utilizzo di memoria (si suppone Nf =K * B): #define B 10 typedef struct T_FORN[B]; typedef struct T_COMP; T_FORN fornitore; T_COMP società; int i; while (!eof(filefornitore)) costo: Nf * sizeof(fornitore) + (Nf /B) * Ns * sizeof(societa); Osservazione: il secondo algoritmo ottimizza l'accesso al file, ma richiede una quantità di memoria di supporto maggiore e una maggiore complessità algoritmica; 3. aggiornamenti sui file insert; delete; update; Esempio 2. Gioco del labirinto. Il file passivo: soluzione che ottimizza l'efficienza durante il gioco, ma limita le dimensioni del labirinto; file attivo: dalla lettura di una riga/colonna ad ogni movimento nel labirinto alla lettura periodica di una porzione del labirinto (finestra).
Esempio 3. Gestione di una rete stradale.
Esempi di operazioni: 1. Controllare che il grafo stradale sia connesso 2. Calcolo del percorso minimo tra due città: 3. Aggiornamenti dei dati della rete a) il file passivo T tutto in memoria
b) il file attivo 1. Controllare che il grafo stradale sia connesso Algoritmo basato sulla matrice di adiacenza: BOOLEAN adiacenza [N,N]; arco i adiacente a arco j implica che adiacenza[i,j] = adiacenza[j,i] = TRUE 2. Calcolo del percorso minimo tra due città: una matrice che riporta in ogni elemento <i,j> se esiste un arco orientato tra i e j: la lunghezza (la minima per più archi); una struttura dinamica per la rappresentazione del grafo. 3. Aggiornamenti dei dati della rete L'aggiornamento è tipicamente un'operazione che coinvolge un arco alla volta. Osservazioni conclusive: File passivo: strutture dati e applicazioni semplici e con file di piccole dimensioni; File attivo: strutture dati e applicazioni più complesse e con esigenze di performance. VARIABILI DINAMICHE globali (statiche) locali (automatiche) dinamiche: a struttura nota a compile-time; allocate e deallocate dal programmatore. Una variabile dinamica non ha nome: definizione della struttura (definizione del tipo); referenza tramite indirizzo; Esempio: typedef struct rec; /* struttura */ rec p= NULL; /* puntatore */ Creazione e distruzione variabili dinamiche import dal modulo di libreria #include <stdlib.h> void malloc(int num); - alloca num caratteri e ritorna il puntatore (NULL s problemi); - il risultato void e il casting: p = (rec *) malloc(size(rec)); - l'allocazione avviene nell'area di Heap - heap overflow - no calloc void free(void *nome pointer); free(p); - la variabile è deallocata - p assume il valore NULL ?? Operatori ammessi sulle variabili di tipo puntatore p=q; p=NULL; assegnamenti if (p==q) o (p==NULL) confronti (<>, ==) *p dereferenziazione aritmetica dei puntatori Esempi e problemia) int a,b; a=b; b) int *p, *q;
c) effetto collaterale: modifica di *p si ripercuote su *q p = (int *) malloc(size(int));
q=p;
if (p==q) . SI if (*p==*q). SI d) q = (int *) malloc(size(int)); . .
if (p==q) . NO if (*p==*q) . ? e) *p=3; *q=3;
if (p==q) . NO IF (*p==*q).. SI f) produzione di garbage: una variabile dinamica diventa irraggiungibile. p = (int *) malloc(size(int)); q = (int *) malloc(size(int));
p=q;
void P() g) dangling reference: una variabile puntatore con indirizzo non valido p = q; free(q);
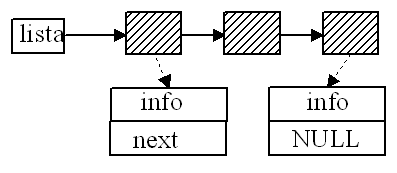
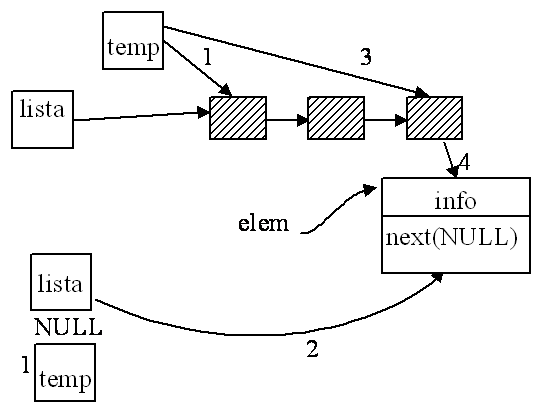
*p= 2; errore in esecuzione Costruttore di tipo ricorsivo (autoreferenza) Strutture dati che coinvolgono più variabili dinamiche. #include <stdlib.h> struct T_elem ; typedef struct T_elem elemento; elemento *lista=NULL, *elem; Creazione di un elemento dinamico: elemento *creael () return(elem); } Strutture definibili attraverso l'uso del tipo ricorsivoLA CODA - Politica di gestione: FIFO (First In First Out) Operazioni principali (ipotesi: la coda non esiste inizialmente - può essere vuota/piena): Visualizza coda Inserisci elemento come ultimo elemento Estrai il primo elemento
void visualizza(elemento *lista) void visualizza(elemento *lista) elemento *insert (elemento *elem, elemento *lista) return(lista)}
void main() Altri esempi LA PILA - Politica di gestione: LIFO (Last In First Out) Operazioni principali (ipotesi: la pila esiste sempre - può essere vuota/piena - vuota all'inizio): Push (inserisci elemento come primo elemento della sequenza) Pop (estrai il primo elemento dalla sequenza) Errori comuni nella gestione di strutture a lista i casi limite (coda vuota, coda con un elemento,.) non considerati; la scansione oltre la fine sequenza: void stampa(int *p) (*non gestita la coda vuota e la sua fine*) rottura di una coda: elemento *insert (elemento *elem, elemento *lista) /* 2 */
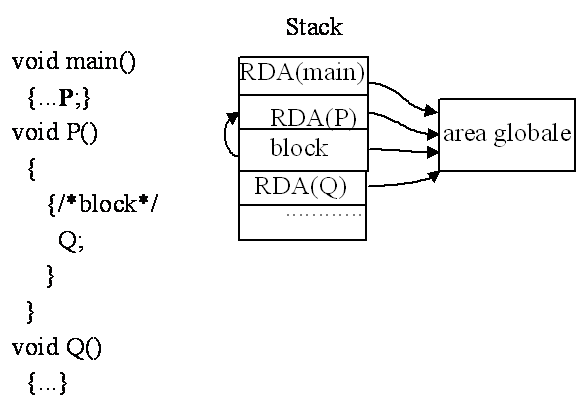
Confronto array e liste di puntatori. Svantaggi dell'ARRAY: dimensione statica, difficoltà negli inserimenti o nelle cancellazioni effettuate in posizioni intermedie in una sequenza ordinata;. Vantaggi dell'array: accesso diretto e non sequenziale agli elementi, algoritmi migliori di ricerca (binaria) se la sequenza è ordinata. PROCEDURE RICORSIVE/* Program P1*/ void funct() (*ricorsione diretta*) void main() /* Program P2*/ extern void funct2(); int a=1; void funct1() void funct2() void main() Permesse dalle regole sul campo di validità. Formulazione ricorsiva di algoritmi: identificare uno o più sottocasi che definiscono la terminazione; determinare il passo ricorsivo: sottocaso del problema tale per cui la soluzione del sottocaso s alla soluzione del problema, ma su un insieme ridotto di dati. Esempio: Calcolo N! Algoritmo risolvente: N=0 N!=1 N>0 N!=N*(N-l)! /*Soluzione non ricorsiva* #include <stdio.h> int N; int fatt(int n) return (tot); void main() /*Soluzione ricorsiva* #include <stdio.h> int N; int fatt(int n) void main() Esecuzione N=3 3*fatt(2) 2*fatt(1) 1*fatt(0) Quali modifiche se n è grande? - long int e %ld Il record di attivazione (RDA) area per il risultato di una funzione; area per i parametri della funzione; indirizzo di ritorno; area per le variabili locali (escluso le dinamiche); RDA(fatt)
Record bloccoarea per le variabili locali (escluso le dinamiche); RDA e stackuna funzione può avere nello stack zero o più RDA; lo stack può essere vuoto o essere pieno; Esempi:
© ePerTutti.com : tutti i diritti riservati | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||