 |
|
| biologia |
|
La scoperta del ruolo genetico del DNA è fatta comunemente risalire al 1928; verso la fine degli anni trenta del novecento, ulteriori esperimenti convinsero la maggior parte dei biologi che alla base dell'ereditarietà c'era un particolare tipo di molecola; intorno agli anni quaranta, gli scienziati sapevano che i cromosomi eucariotici sono costituiti da due sostanze: il DNA e le proteine. Si sapeva che le proteine sono formate da venti tipi di molecole di base (amminoacidi) e hanno varie ed elaborate strutture e funzioni. Il DNA, invece, è composto solo da quattro tipi di molecole di base (i nucleotidi). Nel 1952 i biologi Alfred Hershey e Martha Chase dimostrarono che il materiale genetico del batterifago chiamato T2 che infetta il batterio Escherichia coli è proprio il DNA. I virus che infettano i batteri sono detti batteriofagi o fagi: la parte superiore della testa contiene il DNA. La coda è cava e dotata di sei fibre sporgenti, responsabili dell'attacco del virus alla superficie di un batterio sensibile. I due biologi sapevano che il fago T2 era in grado di produrre nuovi fagi nelle cellule ospiti, ma non sapevano quale componente del fago(se il DNA o le proteine), fosse responsabile di questa azione.
-fecero moltiplicare i fagi T2 insieme a E.coli in una soluzione contenente zolfo radioattivo; quando furono prodotti nuovi fagi, gli atomi di zolfo radioattivo furono incorporati solo nelle loro proteine (perché presenti solo nelle proteine).
-fecero moltiplicare un altro ceppo di fagi in una soluzione contenente fosforo radioattivo (poiché quasi tutto il fosforo contenuto nei fagi si trova nel loro DNA fagico).
Una volta ottenuto il fago T2 marchiato radioattivamente, i biologi furono pronti per effettuare l'esperimento, separando l'esperimento riguardante il fago con le proteine radioattive dai fagi con il DNA radioativo.
Nell'esperimento in cui erano state marcate le proteine, la radioattività si ritrovò nel liquido, contenente i fagi, non i batteri. Quando invece i batteri erano stati infettati dai fagi il quale DNA era marcato, la maggior parte della radioattività si ritrovava nel precipitato costituito da cellule batteriche. Conclusero quindi che il fago T2 inietta il suo DNA all'interno della cellula ospite, lasciando fuori dalla cellula tutte le proteine. Essi dimostrarono che le molecole di DNA iniettato non sono in grado di indurre le cellule a sintetizzare non solo altro DNA fagico, ma anche altre proteine, producendo così fagi completi.
Il DNA e l'RNA sono acidi nucleici costituiti da polimeri o polinucleotidi costituiti a loro volta da una breve sequenza dei quattro differenti tipi di nucleotidi. Ogni nucleotide è formato da: una base azotata (Adenina,Citosina,Guanina,Timina o Uracile), uno zucchero(ha 5 atomi di carbonio e 2/3 atomi di ossigeno) e un gruppo fosfato(formato da un atomo di fosforo P al centro e quattro atomi di ossigeno all'esterno). I nucleotidi sono tenuti insieme da legami covalenti che si formano tra lo zucchero di un nucleotide e il fosfato di quello successivo, questa disposizione dà origine a uno scheletro zucchero-fosfato.
o Il DNA (acido deossiribonucleico) si trova nei nuclei delle cellule eucariotiche. Lo zucchero presente nei suoi nucleotidi è il deossiribosio poiché possiede un atomo di ossigeno in meno rispetto al ribosio. Le basi sono di due tipi:
Timina e citosina sono formati da un anello singolo e sono chiamate pirimidine.
Adenina e guanina hanno una struttura a doppio anello e sono dette purine.
o L' RNA (acido ribonucleico) ha come zucchero presente nei nucleotidi il ribosio ed invece della Timina come base azotata ha l'Uracile.
Franklin scoprì poi che la forma base del DNA era elicoidale, Watson e Crick dedussero che l'elica dovesse avere un diametro di 2nm e che si trattava di una doppia elica costituita da due filamenti polinucleotidici. Scoprirono poi che lo scheletro zucchero-fosfato era collocato all'esterno dell'elica e che, facendo ruotare le basi azotate verso l'interno, esse si appaiavano tra loro in modo molto preciso. Infatti una base azotata purina si appaiava sempre con una base pirimidina del filamento opposto. In breve Watson e Crick capirono che le basi che si complimentarono erano: Adenina con Timina, Guanina con Citosina. Infatti, la quantità di adenina presente in un certo tipo di DNA è uguale alla quantità di Timina, la quantità di Guanina è pari alla quantità di Citosina.
Dal modello della struttura del DNA è chiaro che esso si duplica con meccanismi di stampo. Inizialmente i due filamenti del DNA di partenza si separano, e ciascuno di questi funziona da stampo per formare un filamento complementare. Gli enzimi infine legano tra loro i nuovi nucleotidi per formare i nuovi filamenti di DNA. Questo modello è detto semiconservativo, perché contiene un filamento originario e uno di nuova formazione.
La duplicazione del DNA inizia presso specifici punti di origine della duplicazione, dove le proteine che danno origine al processo si attaccano al DNA e ne separano i filamenti; la duplicazione procede in entrambe le direzioni, creando delle bolle di duplicazione. Nello stesso istante sono presenti migliaia di bolle che, infine, si fondono tra loro dando origine a due nuove molecole complete di DNA.
o Uno dei due filamenti in formazione può essere sintetizzato in maniera continua grazie a un enzima DNA-polimerasi che lega i nucleotidi del DNA muovendosi in direzione del punto di biforcazione del DNA originario.
o Per assemblare l'altro filamento le polimerasi devono lavorare allontanandosi dal punto di biforcazione. Questo nuovo filamento è sintetizzato in brevi segmenti consecutivi a mano a mano che la forcella si apre, così un altro enzima chiamato DNA-ligasi unisce questi segmenti in un unico filamento di DNA.
Oltre a legare tra loro i nucleotidi, le DNA-polimerasi correggono anche la lettura, rimuovendo rapidamente i nucleotidi in possesso di basi azotate non correttamente appaiate, rimuovono il DNA danneggiato da radiazioni o da sostanze chimiche tossiche.
IL TRASFERIMENTO DELLE INFORMAZIONI GENETICHE DAL DNA ALL'RNA E ALLE PROTEINE
Il DNA dirige la sintesi delle proteine, le quali determinano il fenotipo. La serie di comandi va dal DNA del nucleo della cellula all'RNA e alla sintesi proteica nel citoplasma. Le due fasi principali sono:
o Trascrizione_ trasferimento di informazioni genetiche dal DNA a una molecola di RNA
o Traduzione_ trasferimento dell'informazione dall'RNA a una proteina
Sia il DNA che l'RNA sono polimeri costituiti da monomeri posti in sequenze specifiche che contengono un informazione. Nel DNA e nell'RNA i monomeri sono i quattro tipi di nucleotidi differenti tra loro per le basi azotate(A,C,G,T o U). Sequenze specifiche di basi azotate costituiscono i geni del filamento di DNA; un gene è formato da centinaia di miliardi di nucleotidi e una molecola di DNA è formata da migliaia di geni.
o Nella trascrizione viene usato il DNA come stampo, quindi l'RNA appare complementare al DNA. Il linguaggio qui usato è quello degli acidi nucleici.
o Nella traduzione si converte il linguaggio degli acidi nucleici in linguaggio polipeptidico costituito da amminoacidi. La sequenza di nucleotidi della molecola di RNA determina la sequenza degli amminoacidi del polipeptide.
Dal momento che ci sono quattro tipi di nucleotidi nel DNA e nell'RNA, nella traduzione essi devono corrispondere ai 20 amminoacidi conosciuti come monomeri delle proteine. Se ogni base azotata dei nucleotidi rappresentasse un amminoacido, verrebbero codificati soltanto 4 dei 20 amminoacidi. Prendendo a due a due le quattro basi, vi sono soltanto 16 (42) possibili combinazioni non ancora sufficienti per rappresentare tutti e 20 gli amminoacidi. Nel caso delle triplette avremo invece (43)64 possibili combinazioni, più che sufficienti per rappresentare i 20 amminoacidi.(In effetti si è visto che più triplette codificano lo stesso amminoacido).
Il passaggio di informazioni dal gene alla proteina si basa quindi su un codice a triplette: le istruzioni genetiche per la sequenza di amminoacidi di una catena polipeptidica sono scritte nel DNA e nell'RNA sotto forma di una serie di "parole" di tre "lettere" chiamate codoni.
Questo codice è quindi:
Degenerato: perché ho più triplette per ogni amminoacido. Ogni amminoacido sarà quindi identificato da più di una tripletta infatti:
64-3 triplette stop= 61 triplette x 20 amminoacidi
61-2 AUG AGG =59 triplette x 18 amminoacidi
Non ambiguo: una tripletta mi identifica uno e un solo amminoacido.
Universale: per tutti gli esseri viventi dai batteri all'uomo il modo di lettura è lo stesso.
Il primo codone venne decifrato dal biologo americano Nirenberg nel 1961. Egli sintetizzò una molecola di RNA artificiale legando nucleotidi contenenti la stessa base azotata (l'uracile). Questo messaggio poteva quindi contenere soltanto codoni del tipo UUU. Mise poi questo poliU in una soluzione contenente ribosomi e altre sostanze necessarie alla sintesi dei polipeptidi. Tale soluzione tradusse il poliU in un polipeptide contenente un unico tipo di amminoacido (la fenilalanina - Phe). In questo modo dimostrò che il codone UUU dell'RNA codifica per l'amminoacido Phe. Si potè così individuare gli amminoacidi codificati da tutti i codoni. Ci sono però delle eccezioni come la tripletta AUG che ha la funzione di codifica per l'amminoacido Met, ma può fornire anche il segnale di inizio di una catena polipeptidica. I codoni UAA, UAG e UGA sono invece codoni d'arresto che comandano ai ribosomi di far terminare il polipeptide.
Durante la trascrizione i due filamenti di DNA devono separarsi nel punto in cui il processo ha inizio ma uno solo dei due filamenti funziona da stampo. I nucleotidi che costituiscono la nuova molecola di RNA prendono posto uno alla volta lungo il filamento stampo del DNA formando legami idrogeno con le basi azotate. I nucleotidi dell'RNA si legano tra loro grazie all'azione dell'enzima RNA-polimerasi, che individua il punto di inizio della trascrizione grazie a una sequenza nucleotidica chiamata promotore, posta nel DNA vicino all'estremità iniziale del gene.
1.La fase iniziale avviene quando l'RNA-polimerasi si attacca al DNA promotore, si formano così i ponti a idrogeno tra le basi del DNA e quelle dell'RNA.
2.Durante la seconda fase della trascrizione l'RNA si allunga. Mentre continua la sintesi dell'RNA,il filamento appena formato si stacca dal suo stampo di DNA. (si formano legami zucchero fosfato)
3.Infine,l'RNA-polimerasi raggiunge una speciale sequenza di basi azotate del DNA stampo chiamata sequenza di terminazione e se ne distacca(rompendo i ponti a idrogeno).A questo punto l'RNA-polimerasi è nuovamente libera per un'altra azione enzimatica.
Il tipo di RNA che codifica per le sequenze di amminoacidi è detto mRNA(RNA messaggero) perché trasmette l'informazione genetica dal DNA al dispositivo di traduzione delle cellule. Nelle cellule procarioti che la trascrizione e la traduzione avvengono all'interno del citoplasma. Nelle cellule eucariotiche le molecoole di RNA necessarie per la traduzione devono attraversare la membrana nucleare per andare nel citoplasma, dove si trovano i ribosomi. Prima di lasciare il nucleo però, a un'estremità viene aggiunto un piccolo cappuccio (un solo nucleotide di G) e all'altra estremità una lunga coda (una catena di nucleotidi A); il cappuccio e la coda proteggono l'mRNA dall'attacco degli enzimi cellulari e aiutano i ribosomi a riconoscerlo. Moltissimi geni possiedono lunghe regioni interne non codificanti (che interrompono) chiamate introni; le regioni codificanti, ovvero le porzioni del gene che vengono espresse sono dette esoni. Sia gli introni sia gli esoni sono trascritti in RNA. Prima che l'RNA esca dal nucleo,gli introni vengono rimossi e gli esoni si uniscono tra loro per produrre una singola molecola codificante di mRNA, questo processo di "taglia&cuci" è detto splicing. A questo punto, la sintesi proteica continua con la traduzione, un processo complesso a cui prendono parte numerosi dispositivi molecolari:
o L'RNA trasfer (l'RNA di trasporto)
o I ribosomi(organi in cui avviene la sintesi dei polipeptidi).
o Diversi enzimi e un certo numero di fattori proteici.
o Fonti di energia come l'ATP.
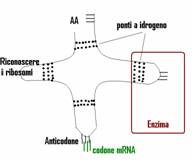 Per la traduzione del messaggio genetico
dell'mRNA nel linguaggio proteico è necessario un particolare tipo di
RNA detto tRNA (RNA di trasporto)
che trasforma i codoni in amminoacidi. Le molecole di tRNA devono agganciarsi
all'amminoacido corretto e riconoscere gli appropriati codoni dell'mRNA. Una
molecola di tRNA è costituita da un unico filamento di RNA formato da
circa 80 nucleotidi. Avvolgendosi e ripiegandosi su se stesso forma regioni a
doppio filamento in cui si appaiano le basi tramite ponti a idrogeno. Il
filamento singolo dell'estremità contiene una speciale tripletta di basi
azotate chiamata anticodone. Ogni anticodone è complementare a un
codone del mRNA. All'altra estremità del tRNA vi è un sito in cui
può attaccarsi un amminoacido. Tutte le molecole di tRNA sono simili,
solo diverse nel sito di attacco dell'amminoacido. Una molecola di tRNA sa
riconoscere il proprio amminoacido solo grazie alla presenza di uno specifico
enzima che lega l'amminoacido al corrispondente tRNA utilizzando una molecola
di ATP come fonte di energia.
Per la traduzione del messaggio genetico
dell'mRNA nel linguaggio proteico è necessario un particolare tipo di
RNA detto tRNA (RNA di trasporto)
che trasforma i codoni in amminoacidi. Le molecole di tRNA devono agganciarsi
all'amminoacido corretto e riconoscere gli appropriati codoni dell'mRNA. Una
molecola di tRNA è costituita da un unico filamento di RNA formato da
circa 80 nucleotidi. Avvolgendosi e ripiegandosi su se stesso forma regioni a
doppio filamento in cui si appaiano le basi tramite ponti a idrogeno. Il
filamento singolo dell'estremità contiene una speciale tripletta di basi
azotate chiamata anticodone. Ogni anticodone è complementare a un
codone del mRNA. All'altra estremità del tRNA vi è un sito in cui
può attaccarsi un amminoacido. Tutte le molecole di tRNA sono simili,
solo diverse nel sito di attacco dell'amminoacido. Una molecola di tRNA sa
riconoscere il proprio amminoacido solo grazie alla presenza di uno specifico
enzima che lega l'amminoacido al corrispondente tRNA utilizzando una molecola
di ATP come fonte di energia.
I Ribosomi sono organuli senza membrana esterna presenti nel citoplasma che coordinano il funzionamento dell'mRNA e del tRNA su cui avviene l'effettivo assemblaggio dei polipeptidi. Un ribosoma è costituito da due subunità costituite entrambe dall' rRNA (RNA ribosomiale).
o Nella subunità più piccola (inferiore) è presente il sito di legame dell'mRNA.
o Nella subunità più grande (superiore) è presente il sito di legame con il tRNA, il sito P (sito peptidico) ospita il tRNA a cui è legata la catena polipeptidica in crescita, il sito A (sito amminoacitico) ospita il tRNA che porta con se l'amminoacido da aggiungere alla catena.
L'anticodone del tRNA si lega al codone del mRNA appaiando le basi azotate. Le subunità del ribosoma tengono unite tra loro le molecole di tRNA e mRNA. Il ribosoma puo così attaccare l'amminoacido dal sito A alla catena polipeptidica del sito P. L'mRNA è fermo perché ancorato, è il ribosoma che si sposta.
Fasi Della Traduzione
In una molecola di mRNA, la sequenza di nucleotidi presenti alle due estremità (cappuccio e coda) non fanno parte del messaggio, ma aiutano l'mRNA ad attaccarsi al ribosoma.
Inizio_
a. Una molecola di mRNA si lega alla subunità ribosomiale più piccola. Uno speciale tRNA di partenza si posiziona legandosi il suo anticodone (UAC) al codone specifico, detto codone d'inizio (AUG)
b. Una subunità ribosomiale più grande si lega a quella piccola dando vita a un ribosoma completo e funzionale. Il tRNA di partenza si colloca nel sito P del ribosoma.
Allungamento_
a. Riconoscimento del codone_ L'anticodone di una molecola di tRNA che porta con se il suo amminoacido si appaia con il codone dell'mRNA posto nel sito A del ribosoma.
b. Formazione del legame peptidico_ Il polipeptide si attacca mediante un legame peptidico all'amminoacido del tRNA posizionato nel sito A.
c. Traslocazione_ Il tRNA del sito P si allontana e il ribosoma si sposta. Il codone e l'anticodone rimangono legati poiché l'mRNA e il tRNA si spostano insieme. Questo movimento porta nel sito A il successivo codone di mRNA da tradurre e il processo puo iniziare di nuovo dalla prima tappa.
Terminazione_
a. L'allungamento continua fino a quando un codone di arresto giunge nel sito A del ribosoma. Il polipeptide completo si libera dall'ultimo tRNA e dal ribosoma, che così si divide nelle sue due subunità.
Qualsiasi variazione avvenga nella sequenza nucleotidica del DNA rispetto alla sua conformazione originale è detta mutazione.
o Sostituzione_ consiste nello scambio di un nucleotide con un altro. Può comportare alcun cambiamento nella proteina , un cambiamento apparentemente non significativo o conseguenze evidenti.
o Inserzione e Delezione_ aggiungere o sottrarre uno o più nucleotidi porta a un polipeptide generalmente non funzionale.
Le mutazioni dovute a errori durante la duplicazione o la ricombinazione del DNA vengono dette mutazioni spontanee. Alcuni agenti fisici (come le radiazioni) o chimici (come sostanze simili alle basi azotate del DNA, che però non si appaiano in modo corretto) rappresentano un ulteriore fonte di mutazione.
Quando il fago va ad attaccare la cellula batterica inietta il suo DNA nella cellula ospite; il DNA fagico assumerà così una struttura circolare. A questo punto può intraprendere due percorsi:
o Nel Ciclo Litico_ Vengono sintetizzati nuovo DNA fagico e nuove proteine, fino a far rompere la cellula (lisi) liberando i fagi.
o Nel Ciclo Lisògeno_ Il DNA si integra in quello della cellula ospite. Una volta inserito, il DNA fagico viene chiamato profago e la maggior parte dei suoi geni è disattivata. La cellula ospite duplica il DNA profagico insieme al proprio DNA cellulare e poi, quando si divide trasmette alle due cellule lie anche il profago. I profagi possono rimanere nelle cellule batteriche per sempre, ma talvolta, in particolari condizioni ambientali, uno di essi si stacca dal suo cromosoma ospite; una volta autonomo il DNA fagico inizia un ciclo litico.
Il virus dell'influenza come molti altri virus che infettano le cellule animali ha un involucro esterno che circonda il rivestimento proteico e sottili estroflessioni (spine) costituite da glicoproteine (proteine legate a zuccheri). L'involucro aiuta il virus a entrare e a uscire dalla cellula ospite. Questo tipo di virus ha come materiale genetico l'RNA al posto del DNA.
Quando il virus viene a contatto con la cellula ospite, le estroflessioni glicoproteiche si attaccano alle proteine recettrici poste sulla membrana plasmatica. L'involucro si fonde con questa membrana consentendo all'RNA e alle proteine del rivestimento di entrare nel citoplasma.
Gli enzimi rimuovono il rivestimento proteico.
Un enzima del virus sintetizza dei filamenti di RNA usando l'RNA virale come stampo.
Questi filamenti hanno la funzione di:
Servire da mRNA per la sintesi di nuove proteine virali
Funzionare da stampi per sintetizzare nuovo RNA virale
Avviene così l'assemblaggio tra il nuovo RNA virale e le nuove proteine virali (del rivestimento)
6. I virus utilizzano la membrana plasmatica della cellula ospite per formare il nuovo involucro.
7. Il virus può abbandonare la cellula senza necessariamente romperla.
L'aspetto esteriore del virus dell'AIDS (HIV) assomiglia a quello dei comuni virus dell'influenza, ha infatti un involucro esterno ed è dotato di estroflessioni glicoproteiche. L'HIV tuttavia, contiene due copie dell'RNA invece che una sola. Inoltre ha un diverso modo di riprodursi, è infatti classificato tra i retrovirus, ossia è un virus a RNA che si riproduce coinvolgendo il DNA. I retrovirus sono così chiamati perché sono in possesso di un enzima chiamato trascrittasi inversa, che è in grado di accelerare un processo di trascrizione in cui viene prodotto DNA utilizzando l'RNA come stampo (anziché il contrario).
La trascrittasi inversa usa l'RNA come stampo per produrre un filamento di DNA
Viene quindi aggiunto un secondo filamento di DNA complementare al primo.
Il DNA a doppio filamento penetra nel nucleo della cellula ospite attraversando la membrana plasmatica e si inserisce nel DNA cromosomico.
Talvolta il DNA del virus (provirus) viene tradotto nelle proteine virali.
Infine i nuovi virus così assemblati (RNA virale e proteine virali) escono dalla cellula e sono in grado di infettarne altre.
L'HIV infetta , e alla fine uccide, diversi tipi di globuli bianchi, importanti per il sistema immunitario che difende il nostro organismo dalle malattie.
La maggior parte del DNA batterico si trova in un unico cromosoma, costituito da DNA circolare e proteine. La duplicazione del DNA nei procarioti avviene per:
o Trasformazione_ consiste nell'acquisizione da parte di un batterio di un frammento di DNA estraneo (appartenente a un'altra cellula batterica) preso dal liquido che circonda la cellula.
o Trasduzione_ qui un frammento di DNA appartenente a una cellula ospite è casualmente inglobato nel DNA fagico. Quando il fago infetta un altro batterio, il DNA "clandestino" è trasferito nella cellula ospite.
o Coniugazione_ avviene quando due cellule batteriche stabiliscono tra loro un contatto. La cellula donatrice "maschile" possiede pili sessuali, alcuni dei quali si attaccano alla cellula ricevente femminile. Tra essi si è formato un ponte citoplasmatico, attraverso cui il DNA della cellula donatrice passa in quella ricevente. La cellula donatrice duplica il proprio DNA a mano a mano che lo trasferisce, in modo che non rimanga priva di geni. Il nuovo DNA una volta entrato riesce a integrarsi nel cromosoma della ricevente, verificandosi un processo simile al crossing-over.
La capacità di una cellula maschile di svolgere la coniugazione è data dalla presenza di uno specifico segmento di DNA detto fattore F, contenente anche un punto di origine della duplicazione del DNA.
o Quando il fattore F è integrato nel DNA del batterio_ questa cellula si coniuga con quella ricevente, il cromosoma maschile comincia così a duplicarsi a partire dal punto d'origine della duplicazione del fattore F. La copia di DNA in formazione si stacca dal cromosoma d'origine e penetra al'interno della cellula ricevente. Così nella cellula ricevente avverrà il crossing-over. In ogni caso la cellula ricevente non conterrà tutto il fattore F, potremo quindi continuare a considerarla femmina.
o Se invece il fattore F è un plasmide, ovvero una piccola molecola di DNA separata dal più grande cromosoma batterico, quando la cellula maschile attacca la cellula femmina, il fattore F si duplica e trasferisce nella ricevente una copia completa. Il plasmide trasferito forma nuovamente un anello nella cellula ricevente e questa diventa "maschio".
|
Privacy
|
© ePerTutti.com : tutti i diritti riservati
:::::
Condizioni Generali - Invia - Contatta
